


今天压测了一下帮朋友优化过的接口,终于能承受c50了。仍然很低,但已经是非常大的突破了,大到不知道有多少倍。(更新:再次优化后可承受c300,但前面c50的过程更有意思)
介绍:
首先系统已经是大型单体应用,数据库没有切分,接口耗时也主要在数据库请求上面。目前最大单表已经超过1千万行,另外还有几个业务表好几百万行,而我优化的这个接口所操作的正是第二大表,9百多万行。 用的阿里云RDS,一主一从,先前都分别已经饱受数据库崩溃的苦难,有时是主库cpu100%,有时是读库cpu100%,也有时是先后轮流100%,每次只能重启,我能体会到朋友心痛的感觉。
读库:
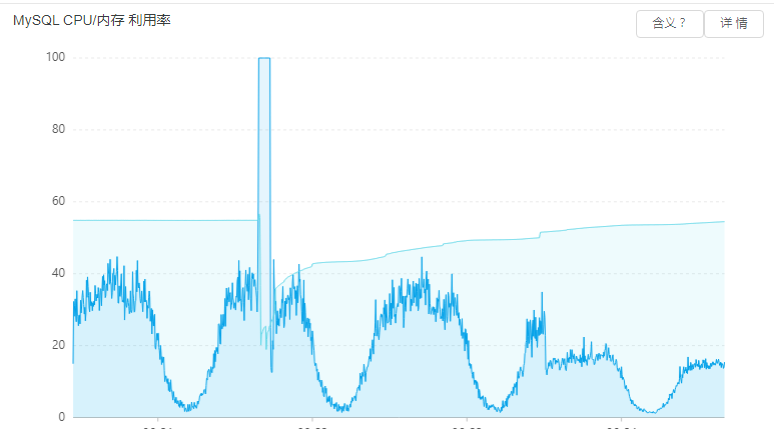
既然记录下来,就先回顾下第一只死耗子吧。那其实算是个bug,不知道前人是遗漏了判断还是怎么,某处接口未对过时的会话进行过滤,产生了无效的数据库查询,并且因为userid为0,虽然用到索引但已经失去性能意义。修复后竟然发现读库cpu就此从26%下降到13%,即便到了一天中的高峰时段,cpu占用仍然不到20%,而看以往的记录是cpu占用会大于40%。
说明在线流量确实比较大,仅仅过滤掉会话超时的请求都能带来如此的效果。
主库:
第二只死耗子也就藏在今天压测的接口中。这是一个用户端的列表接口,在被发现之前,我以为是什么麻烦的事情,毕竟前面优化读库已经把运气用掉一些了。据说前人已经对系统性能整个优化过,而且数据早已达到这个量级。但这个接口单次仍然需要8-9秒才能返回。
本以为这次要用点大动作了,打开代码一看,查询列表数据和查询总条数时,原代码是用同一个条件,分别走了两次查询。窃喜,赶紧用上三板斧第一招:SQL_CALC_FOUND_ROWS,把查询总条数的耗时去掉了,此时接口耗时变为4秒多。
这说明接口的耗时几乎都用在这个查询条件中了,拿出sql去数据库跑下看,果然每次运行平均都在3500ms以上,看来要仔细观察这个sql了。
顺便记载一下,就在上图中第二个白天,正当读库cpu100%的时候,主库还很悠闲。当时重启了两次读库,但cpu仍然没有下来,后来不知道过多久,自己莫名其妙下来了,当时还以为是稳定了,结果发现其实是更大的问题来了:主库cpu升到100%了!这个问题更加严重(我判断正是因为主库故障了导致应用没了读操作,读库才下来的),朋友急到又想花钱升级cpu和内存,似乎只要钱能解决的问题都不叫问题。当时打电话问我怎么办,我只能摇摇头,因为这个数据库配置已经买高了,继续往上加cpu,该100%还照样100%。我心想还不如降配节约点钱,但我当时没说,不然妥妥的被误会。毕竟正在故障中,说旁的也没用,只能让朋友先照老样子重启了,唉,重启真是把万能钥匙,只是每次故障究竟会产生了多少损失,只有朋友自己知道。
这时我突然想起来一首歌词:朋友啊,让我们一起牢牢铭记呀,万事求快,故障和风险来得也快呀。
回到这个sql的优化中来:联表都是用的主键,没什么看头,于是我重点检查了主表的索引,也分析了查询条件有两个可选的索引,其中一个索引一看就知道查询性能会低于另一个索引,于是我又用出三板斧的第二招:FORCE INDEX,指定那个我认为最优的两字段联合索引,然而,整个sql最快时仍然要2800毫秒。
这是什么情况?我觉得我选择的这个索引简直就是针对接口中的查询条件而来的,难道要为这个接口增加其他索引吗?我犹豫了,这个主表正是第二大表,记录超过900万行,有6个索引,索引的硬盘占用和数据大小相当,而且整个库中其他大表已经有不少的索引比数据都大了,而这个接口关系到主库,主库又是那么的不稳定(就在我为某重要项目加班的一个月里,朋友因为主库崩溃打过几次电话要求帮助了,现在我终于有时间了,但我不想给主库的写操作增加负担,而且一时间也弄不清楚哪些索引是不必要的,因为朋友的系统外包方已经几乎不提供服务了 )。
我希望用轻轻走过,不留下太浓重痕迹的方式,既帮朋友解决问题,也不至于让自己陷入逻辑太深。当然这个太理想化了,几乎是不可能的。
中间过程里,清理过主表的历史数据,转移了230万行记录到备份表,还剩下750万行,sql耗时仍然没什么变化。我还使用了uim-ats,以外科手术的方式,把这个接口单独引出去做限流,虽然影响用户体验,可总算也能避免主库崩溃吧,但这并没有真正解决性能问题。感觉做了件无意义的事情,还是继续好人做到底,送佛送到西。
最终的结果,当然是仔仔细细看完了这个接口的逻辑,但真正的优化操作并不涉及任何逻辑,也不是什么高技术含量的东西,就把这句sql做到了5-35毫秒的级别。前面那么多优化想法,竟然抵不过……
我苦笑了,以最不经意的操作达成最大的效果,这算是三板斧的最后一招吗?改好后开始压测。
说到压测,本来先用阿里提供的行业压测平台,因为朋友域名是走到高防ip,发现会有一部分被拦截掉,于是把接口地址改为真实ip,可是:
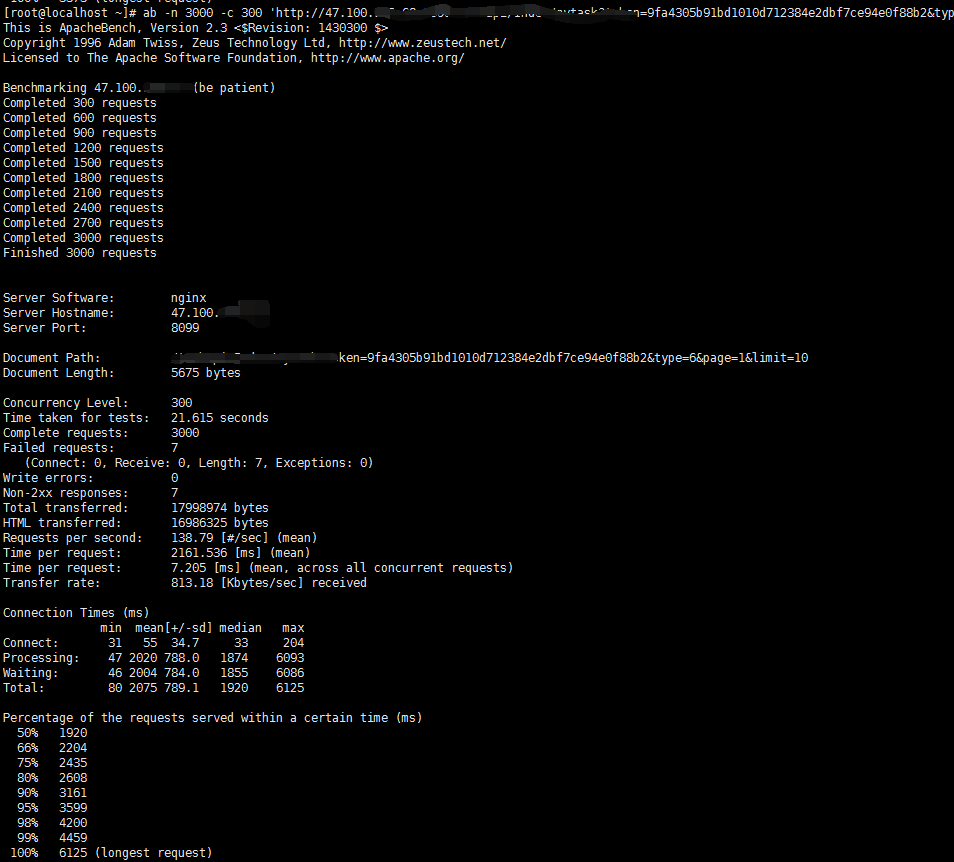
只好用ab了。试了下c50,也就是文章开头提到的数字,延时勉强能接受,当时忘记截图,不过这已经超过我的预期,毕竟我在浏览器单次请求都要100ms,美中不足的是,主库cpu仍然能看到100%的尖峰。
拿一个单次响应都要100ms的接口去压测,我脸上是无光的,虽然主要的sql操作已经降低到极限,但毕竟前面也仔细看了接口逻辑,于是对这100ms中的另一个大头进行了简单优化(把token从mysql改为redis,过程不表),最后整个接口只要60毫秒,减少了mysql操作,这样连同其他相关接口只要用到token的都得到了提升,差不多,佛已经送到西方极乐了,再压测几次,最后得出:c200时,失败率为0,50%的请求能在1291ms内完成,所有的请求在3373ms内完成;c300时,产生了7个失败,50%的请求能在1920ms内完成,所有的请求在6125ms内完成。数据库除了会话数、TPS和流量吞吐等指标因为压测而出现尖峰,CPU基本没有上升,这些已经能够说明现在属于web服务器的线程问题,和数据库没多大关系了。
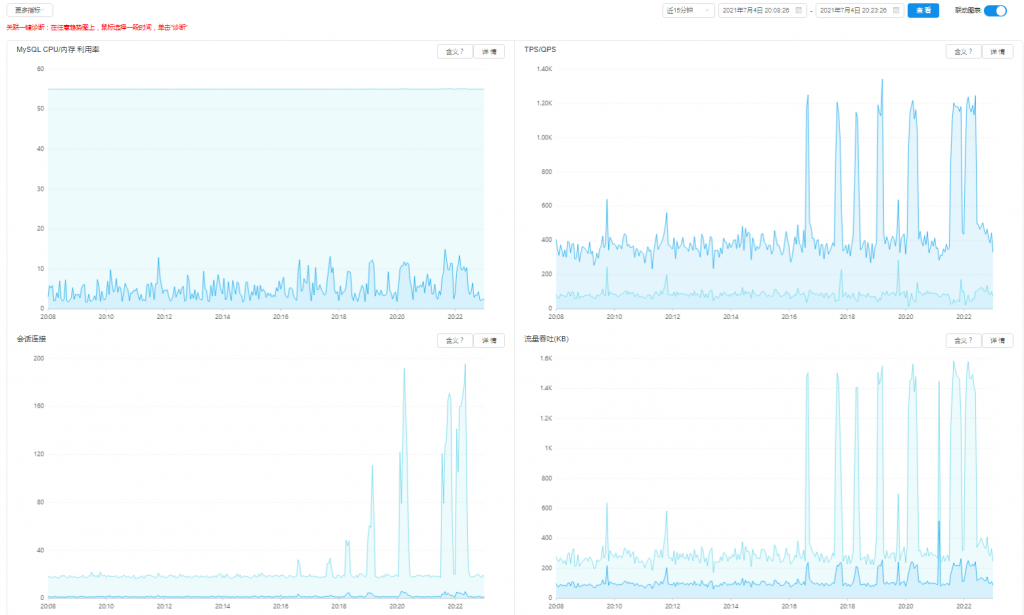
最后,如果不是这套系统不方便迁移,真想立马帮朋友把web服务器改成多台低配,既节约钱,还高可用,而现在,单台十几核加几十GB,所有服务都在上面,又不能让程序跑那么高,空闲着在那儿又觉得浪费。
看来,优秀架构的价值,真的哪哪都能体现啊!