


早有准备要以API架构为题,正好前天在微信群看到我们副总转发的一篇文章:《GraphQL vs REST API 架构,谁更胜一筹?》。由于之前一直在用自己的思维方式处理接口,对GraphQL并不了解。初看此文,了解到GraphQL在数据结构方面,考虑了按照前端的希望来返回数据,以及嵌套分层查询。其中举了个例子:
在 Facebook 的新闻推送中,这种结构允许一个查询返回一个帖子列表、每个特定帖子的评论,以及每个评论的点赞。
以往很多人都是通过传入特定参数来向服务端表示是否需要返回扩展字段和嵌套数据,而这种方式比较固化,灵活性远不能和GraphQL的图状查询相比。
我能理解,GraphQL这样的设计确实可以更简单直观的获取数据,但一开始不认同这种做法,因为在我的思维里面,当需要返回帖子列表并附带帖子的评论以及评论的点赞等关联和嵌套信息时,应当在编写接口时实现,而编写接口发生在定义接口之后,而定义接口这样的工作,应该由同时对相关模块的前端与后端细节实现有主导权的人来做。至于如何优雅的返回嵌套结构的数据,则是该由后端人员结合数据库、缓存及系统整体的设计来实现。API的架构设计不应该为了追求单一的目标而对业务结构与数据库系统可能的演变方向造成阻碍,更不应该过于追求灵活而失去统一控制 。
但毕竟GraphQL是Facebook家的东西,看完这篇文章和底下大神们的评论,我继续去看了下官方的介绍和其他的文章,这才了解到GraphQL其实是一个用于API的QL(query language)。
虽然GraphQL也为后端做了很多设计,可我觉得后端这块阵地可能还是以REST为主,我可以大胆猜测GraphQL的社区里的程序员们,会不会大多是以前端为主?如果真是这样,在重前端的思维中出现 “ask exactly what you want.” 这样的模式也是一种必然,GraphQL的火与当初NodeJs的火,会不会有着相似的原因?
尽管了解得不深,我还是尽可能的找了下GraphQL中我所认为的重点设计。
一个接口请求先被统一的入口或网关进行验证,而后再进入执行,正巧我也是这么设计的;GraphQL生态发展较好,还有像GraphiQL和GraphQL playground这样的工具,更能给人良好的开发体验;内省系统也为开发过程加服务分……
往后还会继续分析GraphQL的特点和发展,目前由于工作量的原因,只能先加到收藏夹了。
虽然GraphQL的整体设计面很广,有很多有意义的特性和细节,值得我们去学习和参考,但我大概率是不会去使用它的,倒不是因为眼前没有时间去仔细研究,而是现在去使用它就是在把简单的问题复杂化,往后编程的门槛会越来越低,只有越简单高效,才越具有吸引力。我也正在往这个方向摸索。
至于RESTful设计模式,我记得大约两三年前HTTP的作者写过一篇文章,链接找不到了,大致是呼吁大家按照作者的思维来“合理的”使用HTTP的请求方式和状态码,以及遵循他们的“URL命名准则”,可惜仍有许许多多的开发者继续保持POST最大化,状态码也是自有一套,更别说URL的资源定位原则了,这导致RESTful只能作为一种设计模式存在而不能形成规范。
我觉得RESTful之所以有这个尴尬的现状,很大的原因是由于HTTP作为应用层的协议,必然会与众多开发者群体中逐渐生长的各个应用开发框架,在某些方向形成冲突。虽然HTTP作为网络协议有先入为主的优势,但他无法将观点和设计理论强加到每个人脑子里。
除了REST和 GraphQL ,另外常被说起的还有RPC、SOAP等等,一般来说是不好放在一起讨论的,毕竟不是完全相同的概念,而且处在不同维度。
我们不能简单的说哪种设计好或者不好,因为各个设计所面对的问题不同,而设计本身也一直在迭代,其所基于的考量也不是一成不变,虽然相对成熟的设计在较长的时间里通常不会有大范围的改变。
如果只从API的架构角度来看,我还是持实用主义,并且有以下几点看法:
1、不盲目追新是正确的;
2、通讯过程不该让接口两端的开发者参与;
3、数据结构是重点;
4、接口网关设计的合理性是架构水平的重要指标。
进入本文的主题,我那个未命名就已“过时”的API架构。
在我的设计中,前端应该首先关注自己需要实现的业务、判断交互中涉及哪些数据对象、最后通过文档和沟通,确定应调用的接口及调用前后的处理逻辑。而后端应该把各个接口看成独立的服务,每个接口都找到相应的负责人,发生人员流动时可以清晰的把接口责任转交给下一个人。接口需求由相应模块的负责人定义,涉及复杂逻辑的接口可以会议讨论。看似多花出一点时间成本,实际很有必要,且带来的益处非常多。
除了把接口的开发和部署关联到责任人,接口代码的质量、开发用时等也可以用来作为评定程序员绩效和能力的指标。另外在整个系统的质量和可维护性上,无论哪个团队负责人或者是项目负责人,都不会愿意看到系统代码中,有越来越多只有写的人自己才知道是干嘛用的东西。对程序员绩效的管理是另一个话题了,后续有空了再另外写。
除此之外,还有一些其他的设计和细节处理,有人喜欢说 show me the code. 好在我一年多前就把这些设计实现出来过并且在团队当中使用。当时还搞了在线代码编辑器,每个接口的开发只需要在页面上写一个对应的接口函数,本地环境都不需要,直接在线开发 ,即时测试并提交部署。之所以说已“过时”,一是由于先前的实现过于粗略,需要重写,二是只使用http的通讯的方案已经成为历史。我不仅同意别人完全使用POST来做接口传输,甚至连HTTP都不是我唯一的选择。
在使用网络进行数据交换时,无论是否使用应用层的http和websocket,还是直接使用tcp/udp,甚至在tcp/udp之上自定义一种协议,这都可以划为API框架的范围,单从接口的开发、调用、执行和返回来说,其实无需关注网络传输的细节。
从web角度考虑,为了在浏览器上使用,我目前同时兼容http/s和websocket,但以websocket为主。如果是在客户端里,或者像在安卓上使用自己的壳,那必然会使用TCP/UDP。总之不管用什么协议来通讯,对接口的开发和调用来说都无关,这没什么疯狂的,微信不就是自定义协议么。
介绍下架构上的实现方案:
接口所在的后端,我把它看成是纯消费端,由接口网关统一接收客户端的接口请求,这样做的目的,是把系统的服务能力具体化为接口消费端的数量,至于接口网关,我目前把它集合在socket长连接服务器上,同样是可以灵活的横向增加,这时接口网关的承载能力也对应到socket长连接的服务器分布节点数量上。socket这边涉及较多的细节设计,后续再以另一篇文章来讲。
既然要做到让接口两端都无须关注通讯,就必须封装好调用方法提供给前端了,也正因为如此,所以我设计了将接口结果直接缓存到客户端的方案,前端调用接口时甚至都不用需要知道返回的数据是来自于云端还是本地缓存,只需要传入控制参数表示是否允许使用缓存即可。关于如何清理前端接口缓存,涉及到更多内容,后续会整理相应的文档。
具体说到缓存的设计,不可避免要考虑后端缓存,很多人首先会想在接口网关上做这件事,但仅仅这样是不够的。能抓住老鼠的猫确实是好猫,但是一个村子里只有村口的人养猫是不行的,而且有的人还是喜欢养狗。这个形容不太直白,我现在先不说那么具体,免得太多人问,后续有眉目了再讲。
除了要考虑给缓存设置多长的有效期,更应该注意有没有特别的事件会导致缓存提前失效?如果有一些缓存可以一直保留,直到收到清除指定再清除掉,这样又能提升很大的系统效能了,我一直在采用这种设计。如果大家把网站的页面也看成这种缓存形式,就能理解我为什么要搞个页面服务器专门用来放静态页面了,这绝不只是为了动静分离。
再想想我们为什么需要缓存?绝大多数都是为了减少数据库的IO压力和缩短程序响应时延。现在已经有了好几级的缓存,不用担心前端程序的响应时延了,而数据库的IO压力,最好是通过分布式来解决了。我现在最想做的事情就是给接口层提供一个标准化的ORM,让后端开发者少去操心数据的分库分表逻辑,直接让ORM去做数据同步、异地多活、分布式事务。这是一个非常有难度的事情,但意义巨大,我还停留在纸上的设计阶段。
不得不提一下我对接口文档的管理所做的设计,新版的接口编辑界面长这个样子:
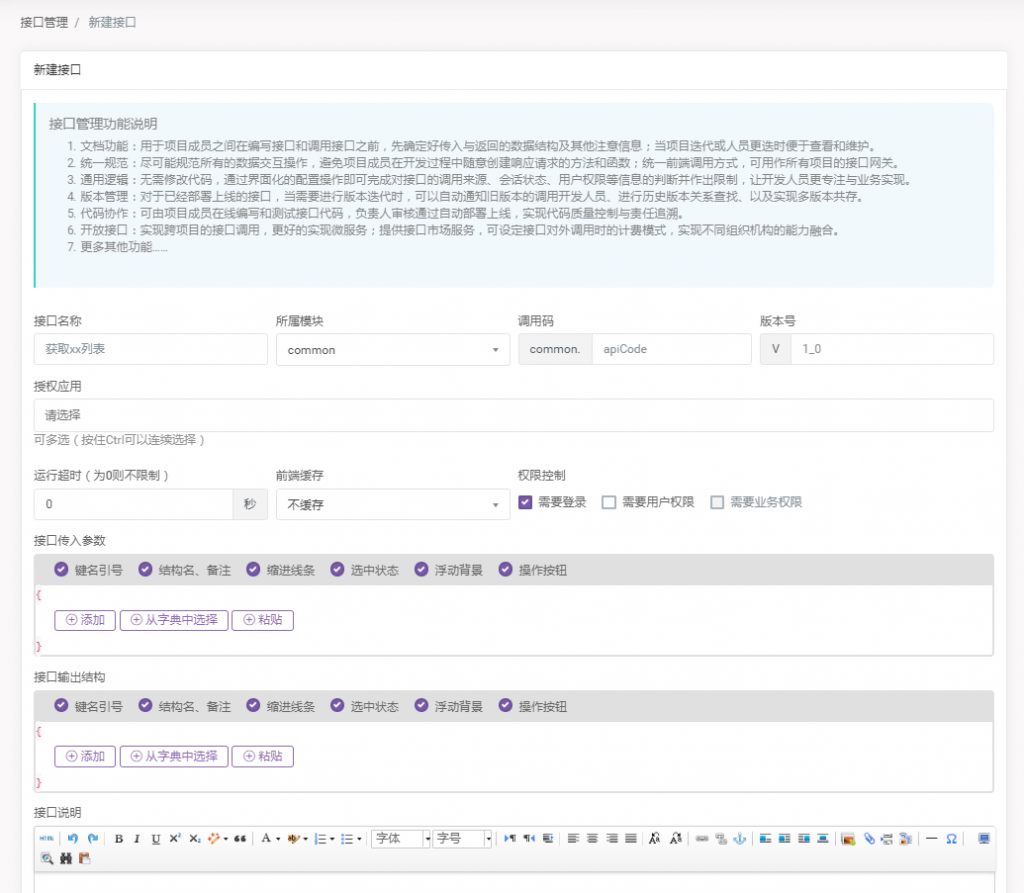
接口调用码和接口版本用于定位前端所请求的接口。其中对接口传入参数和接口输出结构的管理,是按照我自己对管理接口数据结构的理解,做成了我想象的样子。可以添加自定义的数据结构,也可以从字典中选取:

编辑数据结构:
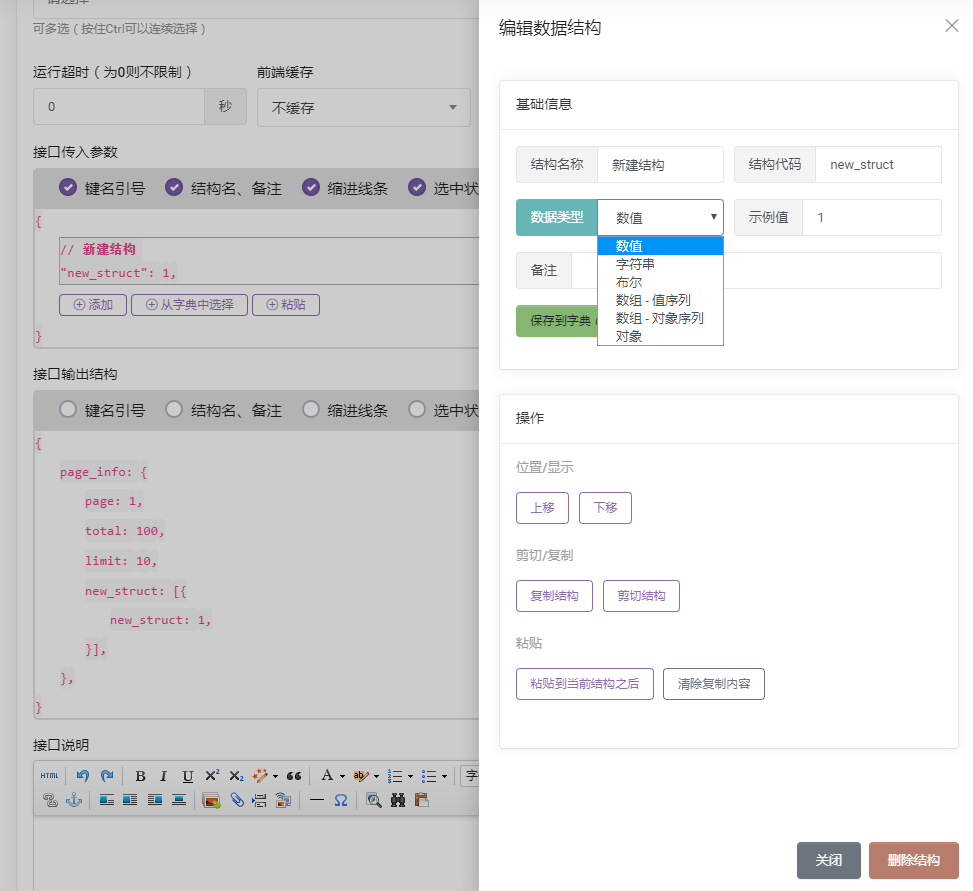
从对接口文档的管理出发,可以有很多延伸,比如接口还没有开发完,通过定义的数据结构,前端就可以请求接口得到示例输出;接口网关也可以按照接口文档的输入参数对请求进行预验证……
有些人天生喜欢创造自己的理论,就连重复造轮子的事情都有大把的人干,何况总有新的领域。
这是我认为的新领域,关于这个已“过时”的API架构,我仍在继续完善,只要有空,本文也会不时更新。如果某一天这个架构终于完善出来,可以给更多的开发者提高效率和质量了,记得它还没有专属的名字哦!